Testing images and text in pdf via python with CI/CD github actions
Ensuring the accuracy and integrity of PDFs generated by your application is crucial, especially for documents like invoices, reports, and certificates. I have seen that is important for a huge amount of companies, which distribute a lot of letters to customers. Automating this validation process can significantly enhance your CI/CD pipeline, ensuring that every generated PDF meets your quality standards before it reaches your users. There are a lot of paid software which can do this well but I want to show you that you can do this also in python open source. In this blog post, we’ll explore how to set up an automated PDF content validation system.
Why Automate PDF Validation?
PDF documents often contain critical information, and any errors can lead to significant issues, such as financial discrepancies or miscommunication. Automating the validation of PDFs ensures that:
- The content is accurate and as expected.
- Key pieces of information are present.
- The visual integrity of the document is maintained.
Tools We’ll or can use Use
To achieve automated PDF validation, we will use the following open-source tools:
- PyMuPDF (Fitz)**: For extracting text and images from PDFs.
- Pillow: For image processing.
- NumPy: For numerical operations during image comparison.
Setting Up Your Environment
First, we’ll set up a Python virtual environment and install the necessary packages.
Create a Virtual Environment
python -m venv pdf_test_env
On macOS/Linux:
source pdf_test_env/bin/activate
Install the Required Packages
pip install pymupdf pillow numpy
Writing the Validation Script
Testcase
We are going to validate an invoice pdf
We’ll create a Python script that extracts text and images from a PDF and validates the against expected values.

The test will be made on the logo, I generated an expected logo and the textvalues.
"Invoice date: 5/6/2024",
"Invoice num.: 20240020",
"Jan klaasen 25G",
"The Netherlands",
"€8000.00",
"VAT: NL 23.80.12.34.B01",
"info@bsure-digital.nl"

But what you also can do is extract the data and images from an invoice template and use this as a baseline for the compare. This is just an example of the possibilities.
Lets dive into the code
import fitz # PyMuPDF
from PIL import Image
import io
import numpy as np
def extract_images_from_pdf(pdf_path):
doc = fitz.open(pdf_path)
images = []
for page_num in range(len(doc)):
page = doc.load_page(page_num)
image_list = page.get_images(full=True)
for img_index, img in enumerate(image_list):
xref = img[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
image = Image.open(io.BytesIO(image_bytes))
images.append(image)
return images
def compare_images(img1, img2, threshold=0.60):
img1 = img1.resize((100, 100)).convert("L")
img2 = img2.resize((100, 100)).convert("L")
img1_array = np.array(img1).astype(np.float32)
img2_array = np.array(img2).astype(np.float32)
img1_array /= 255.0
img2_array /= 255.0
mse = np.mean((img1_array - img2_array) ** 2)
similarity = 1 - mse
return similarity >= threshold
def validate_pdf_images(pdf_path, expected_images_paths):
extracted_images = extract_images_from_pdf(pdf_path)
expected_images = [Image.open(path) for path in expected_images_paths]
if len(extracted_images) != len(expected_images):
print("Number of extracted images does not match the number of expected images.")
return False
for i in range(len(extracted_images)):
if not compare_images(extracted_images[i], expected_images[i]):
print(f"Image {i+1} does not match the expected image.")
return False
print("All images match the expected images.")
return True
def extract_text_from_pdf(pdf_path):
doc = fitz.open(pdf_path)
text_content = []
for page_num in range(len(doc)):
page = doc.load_page(page_num)
text = page.get_text()
text_content.append(text)
return text_content
def normalize_text(text):
return ' '.join(text.lower().split())
def validate_partial_text_in_single_page(pdf_path, expected_texts):
extracted_texts = extract_text_from_pdf(pdf_path)
if len(extracted_texts) != 1:
print("PDF does not contain exactly one page.")
return False
extracted_text_normalized = normalize_text(extracted_texts[0])
for expected_text in expected_texts:
expected_text_normalized = normalize_text(expected_text)
if expected_text_normalized not in extracted_text_normalized:
print(f"Expected text snippet not found in the PDF:")
print("Extracted text:")
print(extracted_texts[0])
print("Expected text snippet:")
print(expected_text)
return False
print("All expected text snippets are found in the PDF.")
return True
# Paths to the PDF file, expected images, and expected text snippets
pdf_path = "jan_klaasen_20240020.pdf"
expected_images_paths = ["image.png"]
expected_texts = [
"Invoice date: 5/6/2024",
"Invoice num.: 20240020",
"Jan klaasen 25G",
"The Netherlands",
"€8000.00",
"VAT: NL 23.80.12.34.B01",
"info@bsure-digital.nl"
]
# Validate the images in the PDF
validate_pdf_images(pdf_path, expected_images_paths)
# Validate partial text snippets in the single-page PDF
validate_partial_text_in_single_page(pdf_path, expected_texts)
This Python script uses the PyMuPDF, Pillow, and NumPy libraries to validate the contents of a PDF document.
Explanation regarding the imports
- fitz (PyMuPDF): A library for PDF document handling. It allows you to open, read, and manipulate PDF files.
- PIL (Pillow): Python Imaging Library used for opening, manipulating, and saving image files.
- io: A core Python module providing the tools to handle various types of I/O operations, used here to handle in-memory binary streams.
- numpy: A library for numerical operations in Python, used here to perform image comparisons.
The script performs two main tasks:
Image Validation:
- Function: validate_pdf_images(pdf_path, expected_images_paths)
- Process:
- Extracts images from the PDF using PyMuPDF.
- Compares each extracted image with expected images using image resizing, grayscale conversion, and mean squared error (MSE) for similarity measurement.
- Outcome: Prints whether all images match the expected images.
Text Validation:
- Function: validate_partial_text_in_single_page(pdf_path, expected_texts)
- Process:
- Extracts text from the single page of the PDF using PyMuPDF.
- Normalizes the text (lowercase, removes extra whitespace).
- Checks if specific expected text snippets are present in the normalized extracted text.
- Outcome: Prints whether all expected text snippets are found in the PDF.
The collection of texts in this example is a list, but you can make this more easy for business analyst and create functionality in excel
Integrating with CI/CD
name: PDF Validation
on:
push:
branches:
- main
pull_request:
branches:
- main
jobs:
validate_pdf:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: |
python -m venv pdf_test_env
source pdf_test_env/bin/activate
pip install pymupdf pillow numpy
- name: Run PDF validation script
run: |
source pdf_test_env/bin/activate
python validate_pdf.py
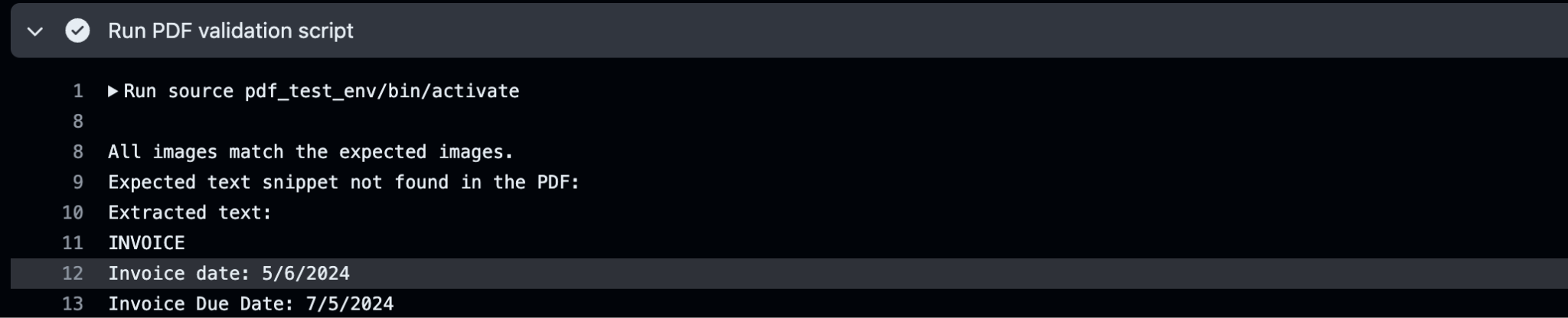
The run in github actions
The image check is successful, bear in mind that I put the threshold on 0.60. Make sure to create a good expected image to compare
def compare_images(img1, img2, threshold=0.60):
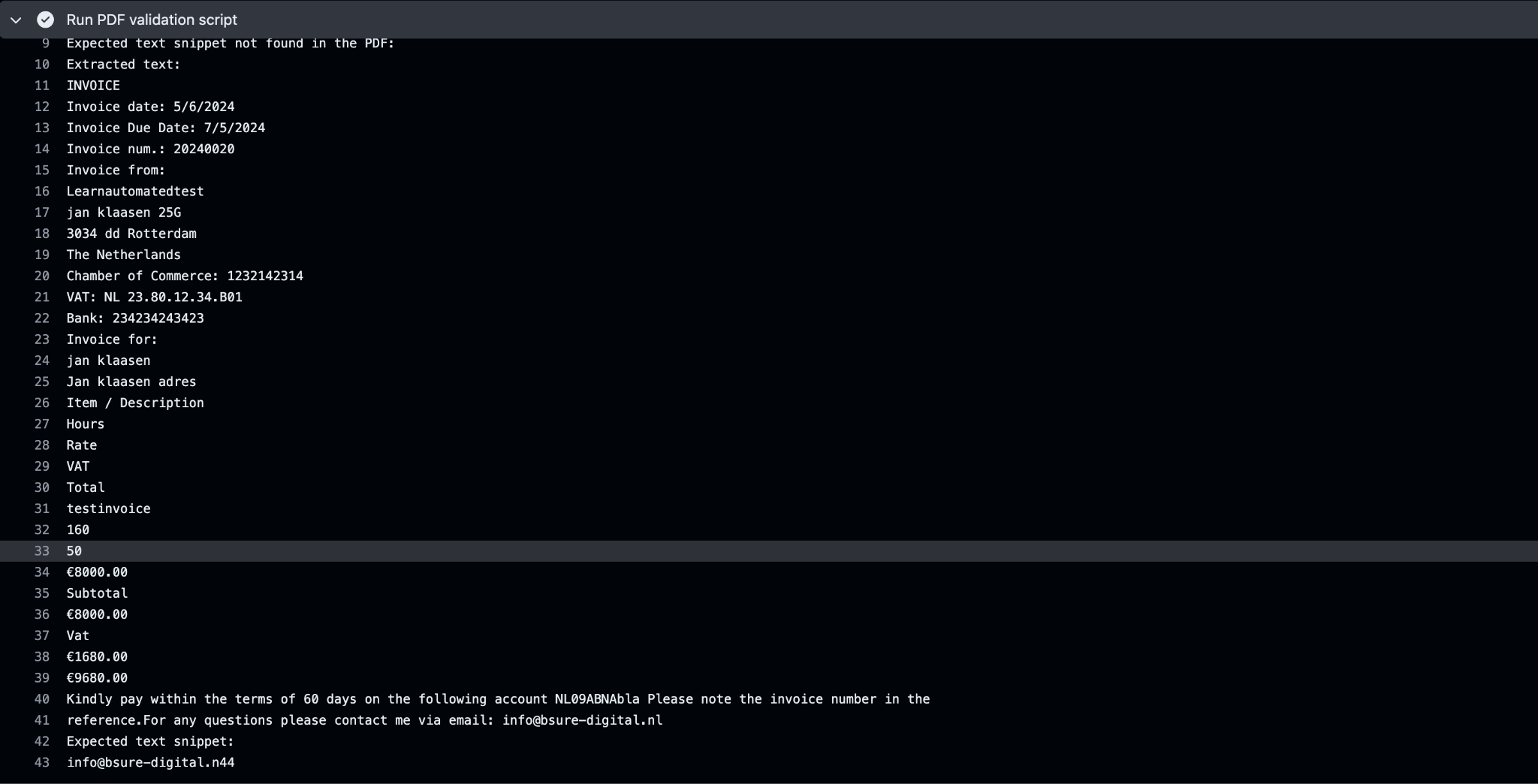
As you can see in my github actions log the text snippet failed info@bsure-digital.n44 instead of info@bsure-digital.nl
Integration with selenium/playwright/cypress
This open source functionality can work together with testautomation web applications that generate PDFs. Let’s say you download the pdf and then use this open source functionality as a separate pipeline to validate the content. This can be a business case
The demo example
I created a demo example here
https://github.com/learn-automated-testing/pdftesterpython
Conclusion
Automating PDF validation in your CI/CD pipeline ensures that every PDF your application generates meets the required standards, saving time and preventing errors. By using open-source tools like PyMuPDF, Pillow, and NumPy, along with Python’s flexibility, you can create a robust validation process that integrates seamlessly into your development workflow and integrate this to your test automation ui api or whatever.With this setup, you can confidently deploy updates knowing that your PDFs are accurate and error-free, enhancing the reliability of the application.