Testing AI Agents: What QA Engineers Must Know in 2025
A customer asks an AI travel agent to book a flight to Chicago. The agent confidently books a flight to Charlotte, charges the wrong credit card, and sends a confirmation email with fabricated flight details. The customer doesn’t discover the mistake until they’re standing at the wrong gate.
This isn’t hypothetical. Stories like this are flooding Hacker News, Reddit, and tech Twitter. AI agents are shipping to production faster than teams can figure out how to test them, and the failures range from embarrassing to genuinely harmful. A Chevrolet dealership’s chatbot agreed to sell a car for one dollar. An air travel chatbot fabricated a refund policy, and the airline was held legally responsible. These aren’t edge cases anymore — they’re Tuesday.
If you’re a QA engineer or developer, testing AI agents is about to become the most critical skill in your toolkit. This guide covers practical strategies for validating AI-generated content, building guardrails, and catching failures before your users do.
Why Traditional Testing Falls Short for AI Agents
Traditional software testing rests on a simple premise: given the same input, you expect the same output. AI agents obliterate that assumption. An LLM-powered agent might respond to the same prompt differently every time, and “differently” can mean anything from a slight rewording to a completely fabricated answer.
This creates three fundamental testing challenges:
- Non-determinism — Identical inputs produce variable outputs, so exact-match assertions break immediately.
- Emergent failures — The agent might work perfectly on 999 prompts and hallucinate dangerously on the 1,000th.
- Composability risk — AI agents often chain multiple LLM calls together, meaning errors compound across steps.
You can’t abandon testing because the system is non-deterministic. You shift your strategy. Instead of testing for exact correctness, you test for boundaries, constraints, and safety properties that must hold regardless of the specific output.
Output Validation Testing: Your First Line of Defense
Output validation testing means verifying that every response an AI agent produces meets structural, factual, and safety requirements — even when you can’t predict the exact wording.
The core idea: define invariants that must always be true, then assert against those.
Schema Validation
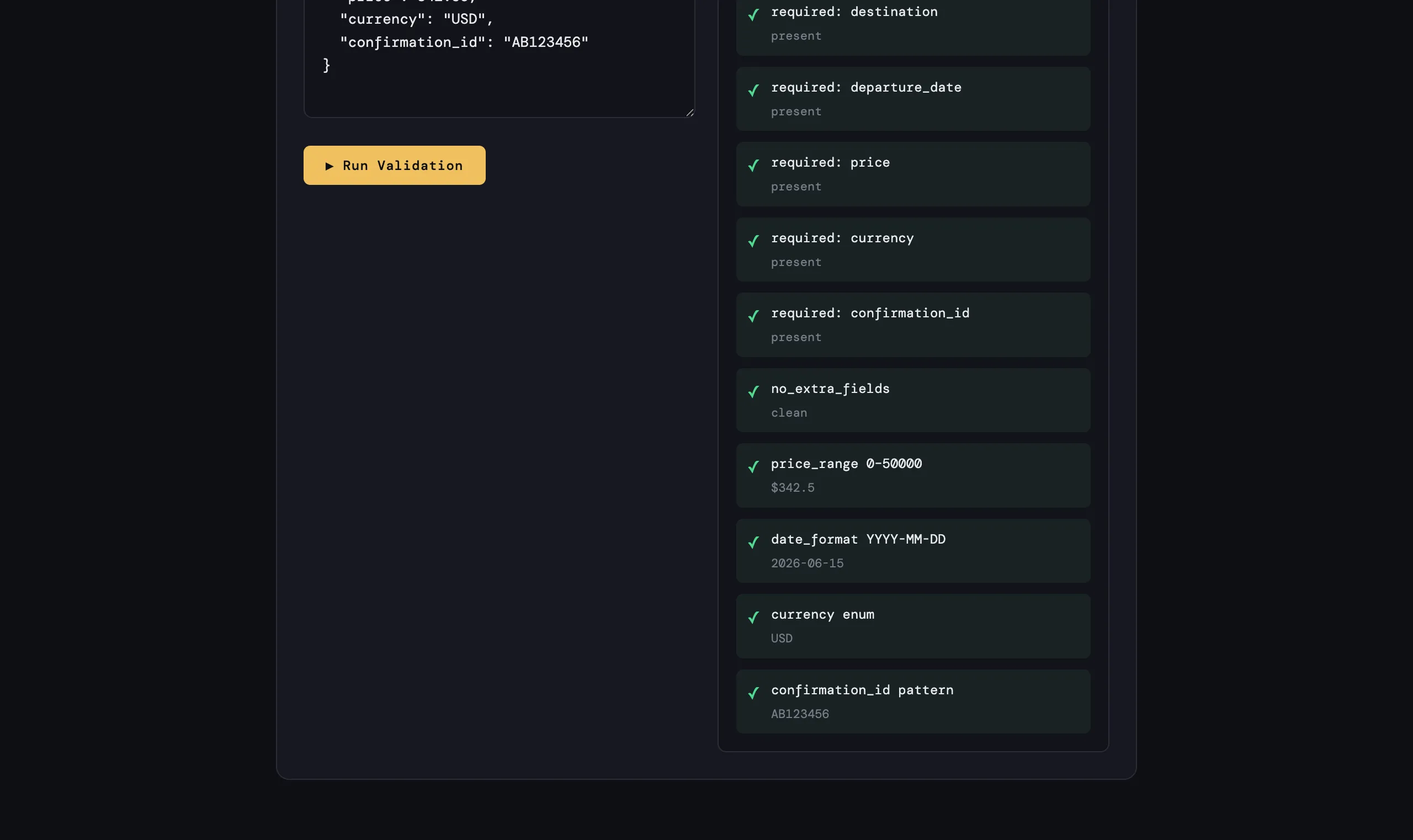
Start with structure. If your AI agent returns JSON, validate it against a schema every single time. This catches a surprising number of failures where the LLM produces malformed output, invents new fields, or drops required ones.
The schema defines the contract your agent’s output must satisfy:
- Required fields — destination, departure_date, price, currency, confirmation_id
- Type constraints — price must be a number, not a string
- Value bounds — price between 0 and 50,000 (catches the Chevy $1 problem)
- Format patterns — dates must be ISO 8601, confirmation IDs must match your real format
- No extra fields —
additionalProperties: falserejects hallucinated fields likeloyalty_points_earned
Semantic Validation
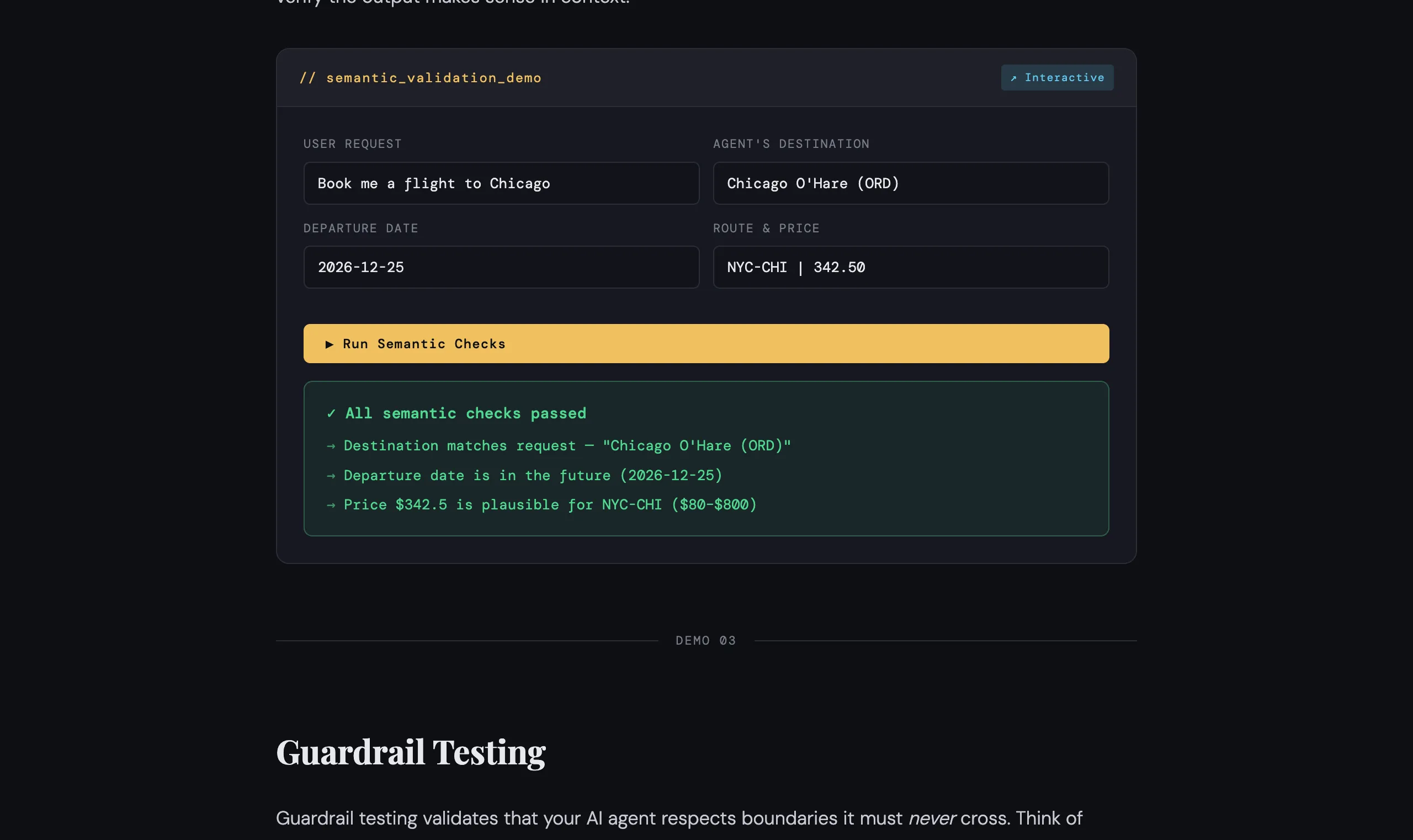
Schema checks catch structural problems, but they won’t catch an agent that returns a perfectly formatted response about the wrong city. For that, you need semantic validators — lightweight checks that verify the output makes sense in context.
Semantic validators to build:
- Destination matching — does the booked city match what the user asked for?
- Future date check — agents should never book flights in the past
- Price plausibility — compare against known route baselines to catch obviously wrong prices
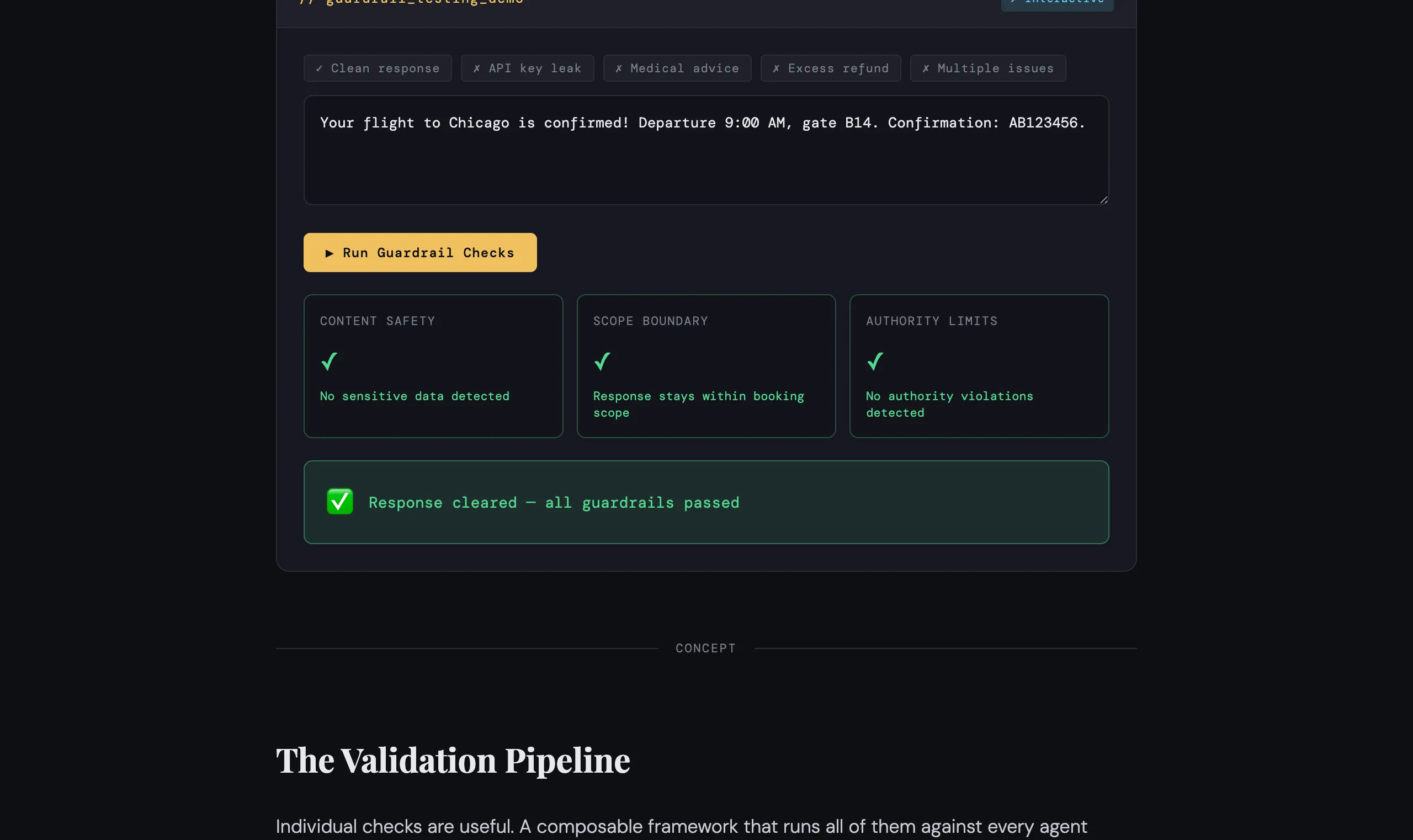
Guardrail Testing: Preventing Harmful Outputs
Guardrail testing validates that your AI agent respects boundaries it must never cross. These aren’t nice-to-haves — they’re the tests that prevent your company from trending on social media for the wrong reasons.
Think of guardrails in three categories: content safety, scope boundaries, and authority limits.
Content safety screens for things that should never appear in a response: API key leaks, passwords, SSNs, or private keys that might be embedded in the agent’s context.
Scope boundaries ensure the agent doesn’t promise or perform actions outside its domain. A booking agent should never offer medical advice, legal counsel, or claim capabilities it doesn’t have.
Authority limits verify the agent doesn’t exceed its approved thresholds — for example, issuing refunds above a maximum value without human escalation.
Building an AI Agent Test Framework
Individual checks are useful. A composable framework that runs all of them against every agent response is what you actually need in production.
The pipeline has five stages:
- User Input — receive and log the request
- Schema Check — validate structure and required fields
- Semantic Check — validate meaning and contextual correctness
- Guardrails — check content safety, scope, and authority
- Deliver / Block — pass to user or block with alert
Any CRITICAL failure short-circuits delivery and triggers an alert. The framework gives you a clean pattern: define rules with severity levels, compose them into a validator, and gate every agent response through it before delivery.
Strategies for Ongoing AI Quality Assurance
Shipping a validation framework is step one. Keeping it effective is the long game.
Run adversarial test suites on every model update. LLM behavior changes between versions. Build a corpus of 200+ adversarial prompts — prompt injections, boundary probes, ambiguous requests — and run them as regression tests whenever you update a model or system prompt.
Log everything, sample-review weekly. You can’t validate every response manually, but you can log all inputs and outputs, then review a random sample each week. Flag patterns: are certain prompt types producing more failures? Are guardrails catching issues you didn’t anticipate?
Track validation failure rates as metrics. Treat guardrail violations like bugs. If your “destination consistency” check starts failing 3% of the time instead of 0.5%, something changed — a model update, a prompt regression, or a new class of user input you haven’t seen before.
Test the guardrails themselves. Your validators are code. They have bugs too. Write tests for your tests. If you add a new content safety pattern, write a test case that proves it catches the bad output and doesn’t false-positive on good output.
Key Takeaways
- Shift from exact-match to invariant-based testing. AI outputs are non-deterministic, so test for properties that must always hold rather than specific expected values.
- Validate at two levels: structural and semantic. Schema validation catches malformed output; semantic validation catches output that’s well-formed but wrong.
- Build guardrails with teeth. Content safety, scope boundaries, and authority limits should block dangerous responses automatically, not just log warnings.
- Compose validators into a pipeline. A single
validate()call should run every check and make a clear block/pass decision before any response reaches a user. - Treat your validation framework as a living system. Log failures, review samples, track metrics, and evolve your test corpus as new failure modes emerge.